1MIT
2Duke University
3Brown University
4University of Washington
5Harvard University
*Equal contribution
Example Vision-Touch-Pose Data
OPENTOUCH demonstrates that hardware-based tactile sensing and pose tracking reveal critical force, contact, and motion cues that vision alone cannot capture.

(a) Although the first three frames show nearly identical hand poses, the tactile signals reveal that in the third frame the hand applies sufficient force to move the chair.

(b) In the first frame, tactile readings clearly indicate contact with the table, ambiguous from RGB alone. In the next two frames, the hand moves out of view, making vision-based pose estimation unreliable; OPENTOUCH provides accurate hardware-tracked poses throughout.

(c) Tactile sensing exposes clear interaction patterns with transparent object that remain difficult to infer from visual tracking alone.

(d) The tactile map captures a subtle middle-finger double-click on a button, a fine-grained motion that even pose tracking may miss. See the supplementary video for the high-fidelity tactile signals and subtle dynamic patterns.
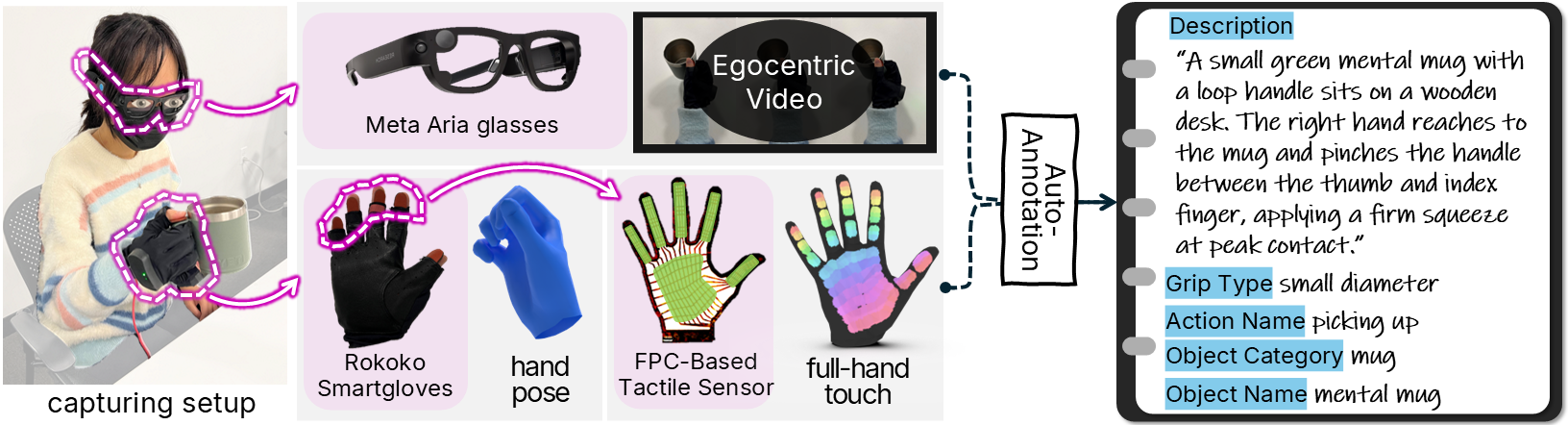
Hardware + Annotation Setup
Meta Aria glasses, Rokoko Smartgloves, and the FPC-based tactile sensor are synchronized at 30 Hz with an average 2 ms latency. High-level descriptions and detailed annotations are automatically generated from the egocentric video and the rendered tactile maps using a large language model.
Tactile Map & Grasp Taxonomy
We visualize accumulated tactile maps across dataset for different grasp types (defined by grasp taxonomy). The spatial pressure patterns strongly correlate with the underlying grasp configuration, demonstrating the accuracy and quality of our tactile data and grasp type annotation.

Annotation Statistics
Sankey diagram visualizing the distribution of dataset labels, including environment, action, grasp type, and object category. In total, OpenTouch contains objects across 14 everyday environments, covering over 8,000 objects from 14 categories.
Tactile retrieval in-the-wild (Ego4D)
OPENTOUCH can act as a tactile database for in-the-wild egocentric video datasets: we demonstrate that in-the-wild video (e.g., Ego4D) can retrieve plausible tactile sequences, enabling large-scale egocentric video to be augmented with contact and force cues. The source videos paired with the retrieved tactile exhibit human behaviors and manipulation primitives strikingly similar to the query.
OpenTouch benchmark
Retrieval + classification
Retrieval benchmark
Bi-modal (Ours only)
R@1 / R@5 / R@10 / mAP
| Direction | R@1 | R@5 | R@10 | mAP |
|---|---|---|---|---|
| video → tactile | 7.15 | 26.73 | 39.74 | 15.47 |
| tactile → video | 7.15 | 26.30 | 39.03 | 15.28 |
| pose → tactile | 6.93 | 21.02 | 30.45 | 13.13 |
| tactile → pose | 7.15 | 21.87 | 30.88 | 13.43 |
Tri-modal (Ours only)
R@1 / R@5 / R@10 / mAP
| Direction | R@1 | R@5 | R@10 | mAP |
|---|---|---|---|---|
| video + pose → tactile | 14.08 | 42.96 | 62.26 | 26.86 |
| tactile + pose → video | 12.72 | 38.53 | 53.18 | 23.46 |
| video + tactile → pose | 15.44 | 43.39 | 57.61 | 26.86 |
- Finding 1: Bi-Modal retrieval. The symmetry across both directions suggests that learned representation is genuinely multimodal rather than biased toward a single modality.
- Finding 2: Multi-modal outperform unimodal. Multimodal inputs offer complementary information that reduces retrieval ambiguity, as video provides global scene context, pose encodes kinematics, and tactile captures local contact and force.
Classification benchmark
| Modality | Action Acc. (RN18) | Action Acc. (Lite-CNN) | Grasp Acc. (RN18) | Grasp Acc. (Lite-CNN) |
|---|---|---|---|---|
| V | 40.26 | — | 57.45 | — |
| P | 33.22 | — | 46.32 | — |
| T | 29.95 | 31.59 | 60.23 | 57.12 |
| T + P | 28.31 | 27.00 | 60.72 | 62.19 |
| T + V | 30.11 | 32.73 | 51.72 | 65.47 |
| T + P + V | 35.02 | 37.32 | 55.65 | 68.09 |
- Finding 1: Tactile is highly informative for grasp type, reflecting that grasp relies on local contact geometry.
- Finding 2: Actions recognition depend on higher-level global context provided by video modality.
Citation
BibTeX
@misc{song2025opentouchbringingfullhandtouch,
title={OPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction},
author={Yuxin Ray Song and Jinzhou Li and Rao Fu and Devin Murphy and Kaichen Zhou and Rishi Shiv and Yaqi Li and Haoyu Xiong and Crystal Elaine Owens and Yilun Du and Yiyue Luo and Xianyi Cheng and Antonio Torralba and Wojciech Matusik and Paul Pu Liang},
year={2025},
eprint={2512.16842},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2512.16842},
}
Acknowledgment
We thank the MIT Office of Research Computing and Data (ORCD) for support through ORCD Seed Fund Grants, which provided access to 8×H200 GPUs and additional funding support. We also thank the NVIDIA Academic Grant Program for GPU support, Murata, and Analog Devices for supporting this work through the MIT Gen AI Impact Consortium. Any opinion, findings, and conclusions or recommendations expressed in this material are those of the authors and do not necessarily reflect the views of NVIDIA, Murata, and Analog Devices.
Like & Contact
Say hi / request access / collaborations